Error statement
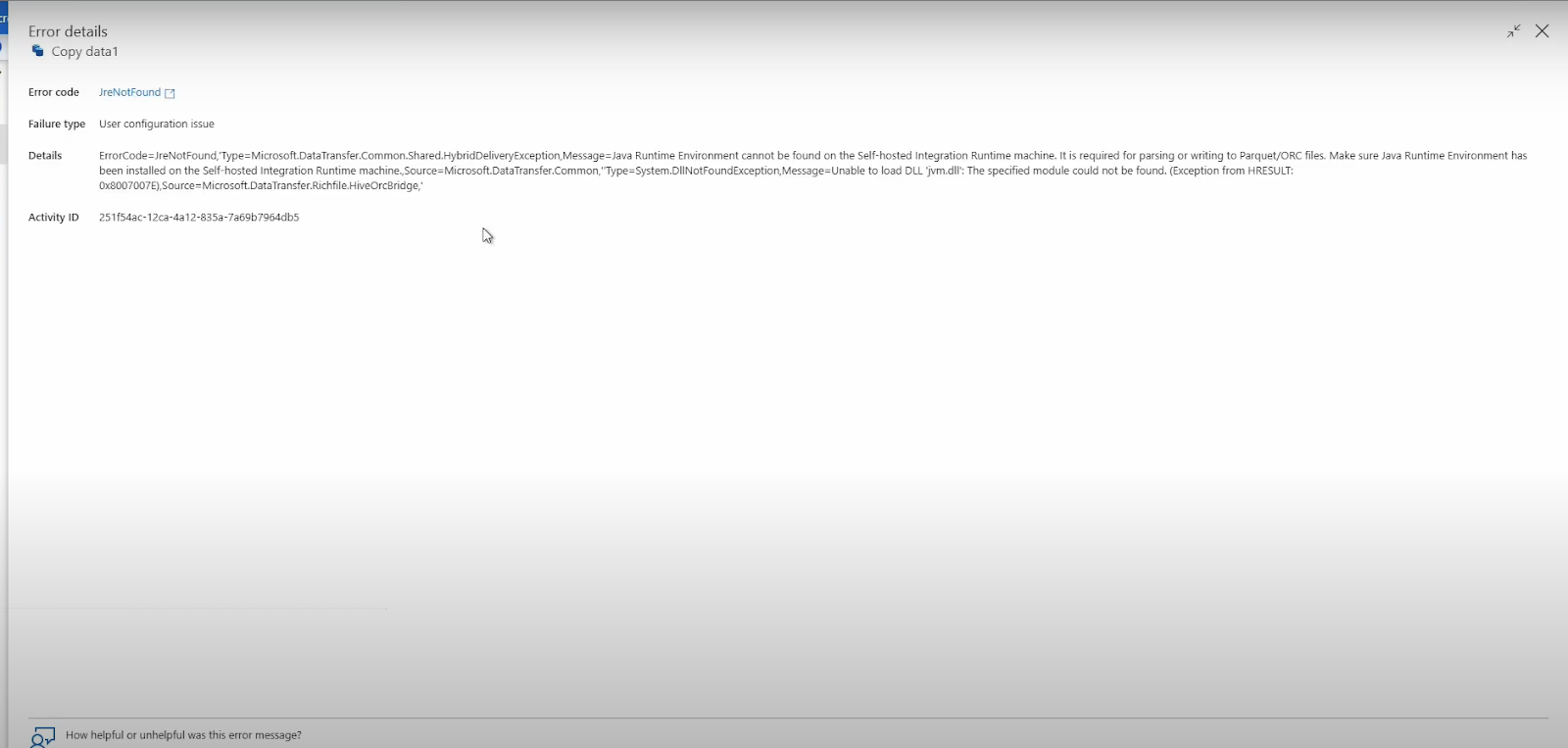
While troubleshooting a data migration issue on Azure Data Factory (ADF), I encountered a “JRE not found” error. This error arose due to the lack of a Java Runtime Environment (JRE) on my machine, which caused conflicts with handling Parquet files. If you’re facing similar issues, this article will explain why this problem occurs and provide a detailed guide to resolve it. For a more in-depth explanation, feel free to check out the accompanying video.
I have set up an ADF pipeline to move data from my on-premises SQL environment to ADLS as parquet files. I created my integration runtime using a self-hosted integration runtime. Everything seemed fine—source, sync—but then I hit a blocker. I kept getting an error saying JRE was not found. So, what’s going on?
What’s causing this JRE issue?
Luckily, Microsoft’s documentation sheds some light on this. From this documentation, we can see that the issue is a parquet format problem. You can check that out here: https://learn.microsoft.com/en-us/azure/data-factory/format-parquet#using-self-hosted-integration-runtime.
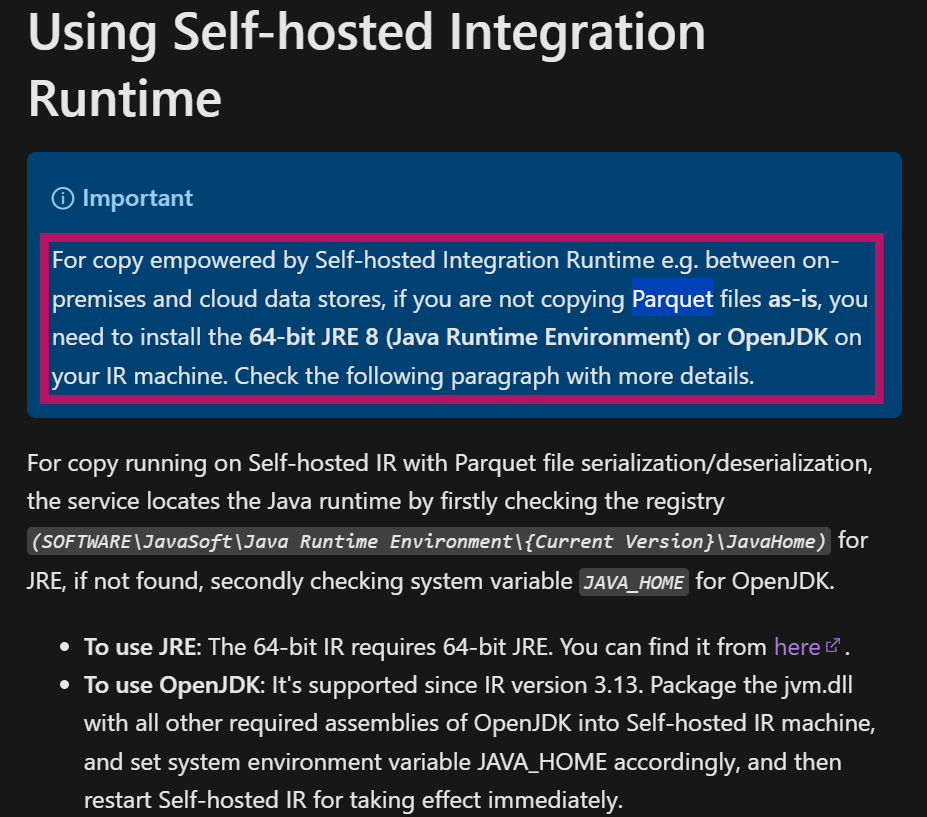
This error is thrown because the Parquet file format requires certain capabilities that aren’t supported without the Java Runtime Environment (JRE) installed on my machine.
According to the documentation, if you’re using a Self-hosted Integration Runtime (IR) for copying data between on-premises and cloud data stores, and you’re not copying Parquet files as-is, you must have a 64-bit JRE or OpenJDK installed. The Self-hosted IR acts as a bridge, enabling secure data transfer, but it relies on JRE to handle the Parquet format’s specific requirements during the transformation process. Without the appropriate JRE setup, the system can’t interpret the Parquet format correctly, leading to an error.
Solution
To fix this, I had to install a 64-bit version of JRE or OpenJDK on my machine. This installation will ensure that the Self-hosted IR can effectively manage the Parquet format, allowing the data migration to proceed smoothly without any format conflicts. Once the JRE is installed, the Self-hosted IR should be able to handle the file transfer seamlessly, converting the SQL database data into Parquet format as intended.

So we’re going to be using the JRE for this. To get this into your local desktop, you can click on download.
After installing JRE, I’ll head back to Azure Data Factory (ADF) and rerun my pipeline. This should resolve the issue.
Here’s a quick overview of my pipeline setup: I’m using the Copy Data tool to transfer data from my SQL database to my Data Lake.
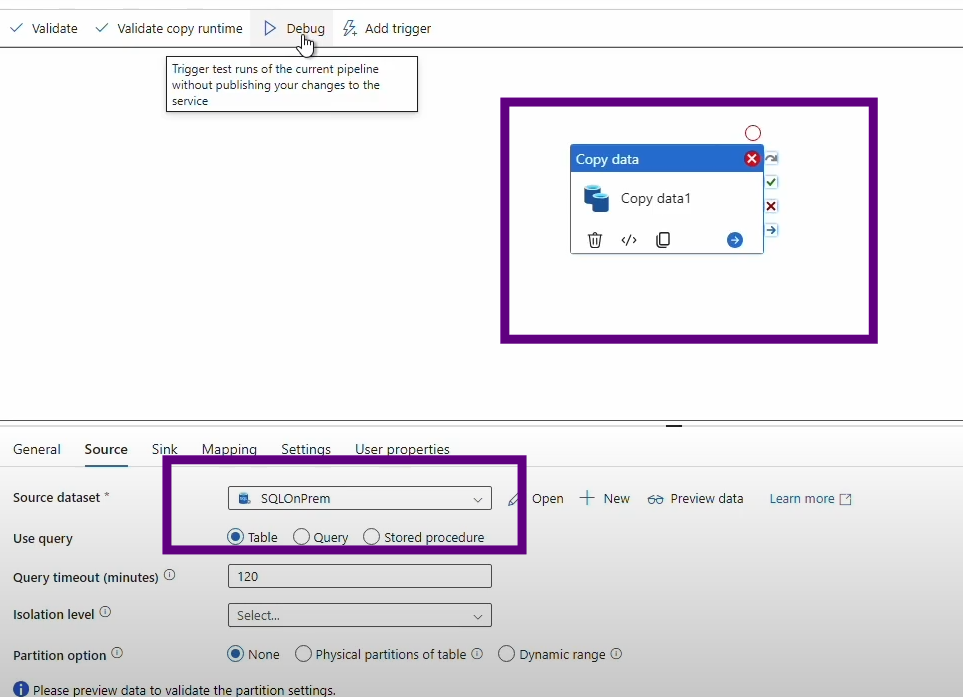
With the JRE now installed, I’m ready to revisit the process. The pipeline begins by extracting data from the SQL database and moving it to a designated folder in the Data Lake, converting it into Parquet format along the way. The Copy Data tool orchestrates this data movement, ensuring that the data is correctly formatted and stored in the target location.
Now that the JRE is in place, it should enable the necessary processing capabilities for handling parquet files within the self-hosted integration runtime. With this configuration ready, I’ll proceed to debug the pipeline again, expecting a smooth data migration without encountering the previous format conflict errors.
Note that the folder hasn’t been created yet. When I run this successfully, the folder should pop up.
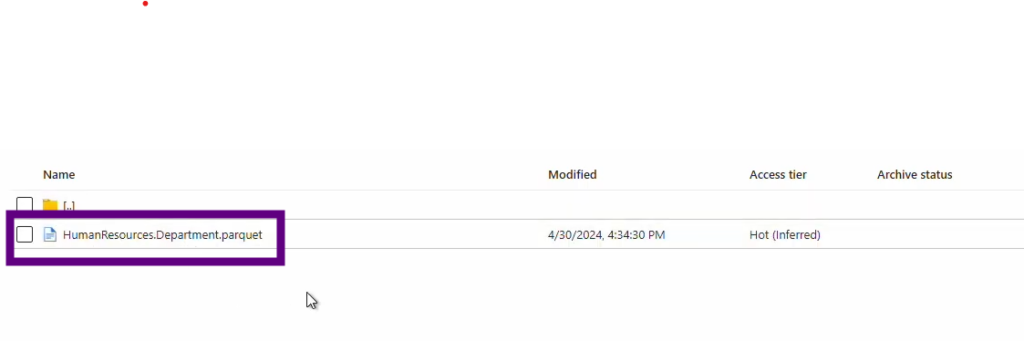
My folder is now in the Data Lake. After refreshing and checking under Tutorials, I see the new folder created from my SQL database data.
I hope this helps solve your error. Do you have any comments or questions? Drop them below, and I’ll get back to you ASAP. Thanks for reading.