“Good data models are like good architecture…” — Clive Finkelstein
One of the easiest ways to understand data modeling is by thinking of it as a blueprint. A blueprint is a detailed plan that guides the construction of something, like a building. Imagine trying to build a skyscraper without a blueprint—things would fall apart quickly. Just like architects use blueprints to design buildings, data engineers (and anyone creating a data product) need a plan to organize and structure data effectively. This plan is called a data model, and it’s the foundation of any data-driven project. Without a data model, data can become messy, hard to manage, and nearly impossible to use properly.
In this article, I explain data models and show you how to design one using a sample music database. If you’d like a more detailed explanation, you can also watch the video embedded in the article for a step-by-step guide.
What is a Data Model?
A data model is an abstract representation of the elements within a system and the relationships between them. It provides a systematic way to define and manipulate data, guiding how data is stored, retrieved, and updated.
Essentially, a data model is a conceptual framework that describes how data is interconnected and how it flows through an organization or system.
Key Components of a Data Model
Entities: These are objects or concepts that exist independently and have unique identifiers. In a business context, entities might include customers, products, or orders.
Attributes: These are characteristics or properties of an entity. For example, a customer entity might have attributes like name, email, and phone number.
Relationships: These define how entities interact with each other. Relationships can be one-to-one, one-to-many, or many-to-many, depending on the nature of the data.
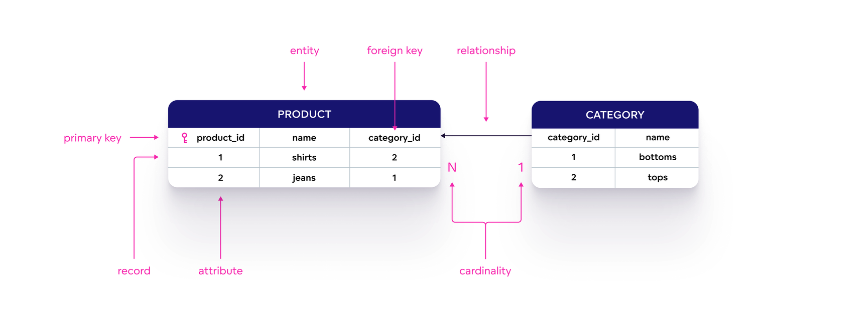
Image source: Good Data
Importance of Data Models
Data models play a critical role in various aspects of system development and data management:
Data Consistency
In any system, it’s essential that data remains consistent across different parts of the application. Imagine an online shopping platform where the price of an item is stored in multiple places—one in the product catalog, another in the shopping cart, and yet another in the order history. Without a consistent data model, these different representations of the price could easily become mismatched, leading to errors like customers being charged the wrong amount. A data model ensures that data is stored in a standardized format, keeping everything consistent and accurate. For instance, a relational data model would define that the price should be stored in a single table and referenced whenever needed.
Efficient Data Access
Data models also play a key role in making data access efficient. When data is well-structured, it’s easier to retrieve and update. For example, think about a social media platform with millions of users and billions of posts. A well-designed data model can ensure that even with massive amounts of data, users can quickly find the content they’re looking for, whether that’s a friend’s profile, a specific post, or search results. In contrast, a poorly structured data model might slow down the entire system, leading to long load times and a frustrating user experience. This efficiency becomes even more critical when systems scale, handling more users and data over time.
Communication Tool
Data models serve as a bridge between different groups working on a project. Imagine a scenario where business analysts are designing the requirements for a new inventory management system. They need to communicate their needs to developers, who will build the system, and to database administrators, who will set up the underlying database. A well-defined data model provides a common language for all these stakeholders, ensuring that everyone understands how the data should be organized and used. This reduces the chances of miscommunication and helps the project run smoothly. For example, in healthcare, a data model might outline how patient information is stored and accessed, ensuring that doctors, developers, and administrators all have the same understanding of the system’s structure.
Foundation for Database Design
A strong data model is the blueprint for designing a reliable database. In industries like finance or e-commerce, where data integrity is critical, a well-designed data model ensures that the database can handle large amounts of transactions while remaining secure and performant. For example, in a banking system, the data model would define how customer accounts, transactions, and balances are linked, ensuring that every transaction is recorded accurately and that the system can scale as more customers join. This foundation is vital for creating databases that are both scalable and maintainable. Without it, adding new features or expanding the system could lead to significant problems, including performance bottlenecks and data corruption.
Practical Example: Building a Music Database with SQLite
In this example, we’ll build a simple music database that stores information about artists, genres, albums, and tracks. You can download the dataset on GitHub
Let’s Code
- Creating a Data model Diagram
- Setting Up the Database
- Defining the Database Schema
- Parsing and Populating the Database from CSV
- Inspecting Your Database
Step 1: Create a Data model Diagram
Below is the model diagram that describes the entities and relationships between them
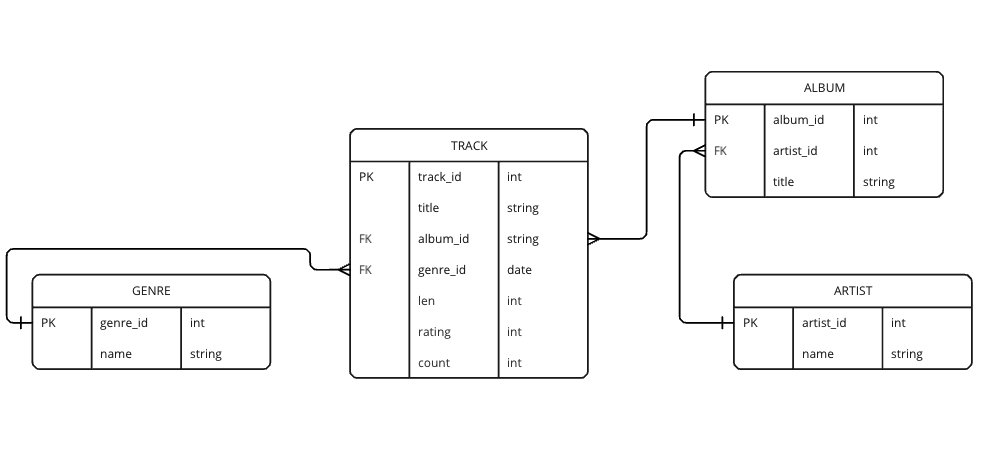
Step 2: Setting Up the Database
The first step in designing our data model is to set up an SQLite database. For this tutorial, we’re going to create a database named trackdb.sqlite and define tables for artists, genres, albums, and tracks. Here’s the Python code that handles this setup:
import sqlite3
conn = sqlite3.connect('trackdb.sqlite')
cur = conn.cursor()
cur.executescript( '''
DROP TABLE IF EXISTS Artist;
DROP TABLE IF EXISTS Genre;
DROP TABLE IF EXISTS Album;
DROP TABLE IF EXISTS Track;
CREATE TABLE Artist (
artist_id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT UNIQUE,
name TEXT UNIQUE
);
CREATE TABLE Genre (
genre_id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT UNIQUE,
name TEXT UNIQUE
);
CREATE TABLE Album (
album_id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT UNIQUE,
artist_id INTEGER,
title TEXT UNIQUE
);
CREATE TABLE Track (
track_id INTEGER NOT NULL PRIMARY KEY
AUTOINCREMENT UNIQUE,
title TEXT UNIQUE,
album_id INTEGER,
genre_id INTEGER,
len INTEGER, rating INTEGER, count INTEGER
);
'''
Step 3: Defining the Database Schema
The database schema defines the structure of your data. In this case, we have four tables:
- Artist: Stores information about the artist, with
artist_idas the primary key and a uniquename. - Genre: Stores genres, with
genre_idas the primary key and a uniquename. - Album: Stores albums with references to the artist who created the album.
album_idis the primary key. - Track: Stores track information, including references to the album and genre, along with metadata like length, rating, and play count.
Each table is related to others through foreign keys, which helps in creating a normalized, structured database.
Step 4: Parsing and Populating the Database from CSV
Now that we have the tables set up, the next step is to populate them with data. In this example, we’ll use a CSV file (tracks.csv) that contains information about tracks, including track name, artist, album, genre, length, rating, and play count.
Here’s how you can use Python to read the CSV file and insert the data into the appropriate tables:
# Open and read the CSV file containing track data
handle = open('tracks.csv')
# Process each line in the file
for line in handle:
line = line.strip()
pieces = line.split(',')
if len(pieces) < 7: continue
name = pieces[0]
artist = pieces[1]
album = pieces[2]
count = pieces[3]
rating = pieces[4]
length = pieces[5]
genre = pieces[6]
# Insert or ignore the artist
cur.execute('''INSERT OR IGNORE INTO Artist (name)
VALUES (?)''', (artist,))
cur.execute('SELECT artist_id FROM Artist WHERE name = ?', (artist,))
artist_id = cur.fetchone()[0]
# Insert or ignore the genre
cur.execute('''INSERT OR IGNORE INTO Genre (name)
VALUES (?)''', (genre,))
cur.execute('SELECT genre_id FROM Genre WHERE name = ?', (genre,))
genre_id = cur.fetchone()[0]
# Insert or ignore the album
cur.execute('''INSERT OR IGNORE INTO Album (title, artist_id)
VALUES (?, ?)''', (album, artist_id))
cur.execute('SELECT album_id FROM Album WHERE title = ?', (album,))
album_id = cur.fetchone()[0]
# Insert or replace the track
cur.execute('''INSERT OR REPLACE INTO Track
(title, album_id, genre_id, len, rating, count)
VALUES (?, ?, ?, ?, ?, ?)''',
(name, album_id, genre_id, length, rating, count))
conn.commit()
This script reads each line from the CSV file, extracts the necessary information, and inserts it into the corresponding tables in the database. The use of INSERT OR IGNORE ensures that duplicates aren’t inserted into the tables.
Step 5: Inspecting Your Database
Once your script has run successfully, you’ll have a fully populated SQLite database. You can inspect the data using any SQLite browser or command-line tool. Tools like DB Browser for SQLite make it easy to view your tables, run queries, and verify that the data was inserted correctly.