If you clicked on this article, I’m guessing you’re curious about the world of Generative AI—maybe a little excited, maybe a bit overwhelmed. That’s totally normal. You’re not alone. It’s certainly the rave of the moment. Think of this piece as a friendly, one-on-one conversation, where we talk about AI again and hopefully arrive at something very useful for both personal and enterprise applications. The first question that pops up is, “Why the buzz, especially within the enterprise ecosystem?”
Let’s start with the big picture. Everyone’s talking about GenAI right now because it’s not just a fancy tech craze—it’s a practical solution that’s helping businesses save money, automate tedious tasks, and create entirely new products. The MIT Tech Review reports that 71% of CIOs plan to build custom large language models (LLMs). Why? Because the difference between a generic chatbot and a carefully trained AI can be the difference between losing customers and wowing them.
I recently got an email from Databricks about what they call “The Big Book of Generative AI” and found it quite interesting, so I thought I’d use it as the building blocks for this article. Databricks laid out an easy-to-follow, five-stage roadmap in this publication. It could be helpful to think of it like a series of stepping stones that guide you from “What even is AI?” to “Oh, I’m running AI at scale now.”
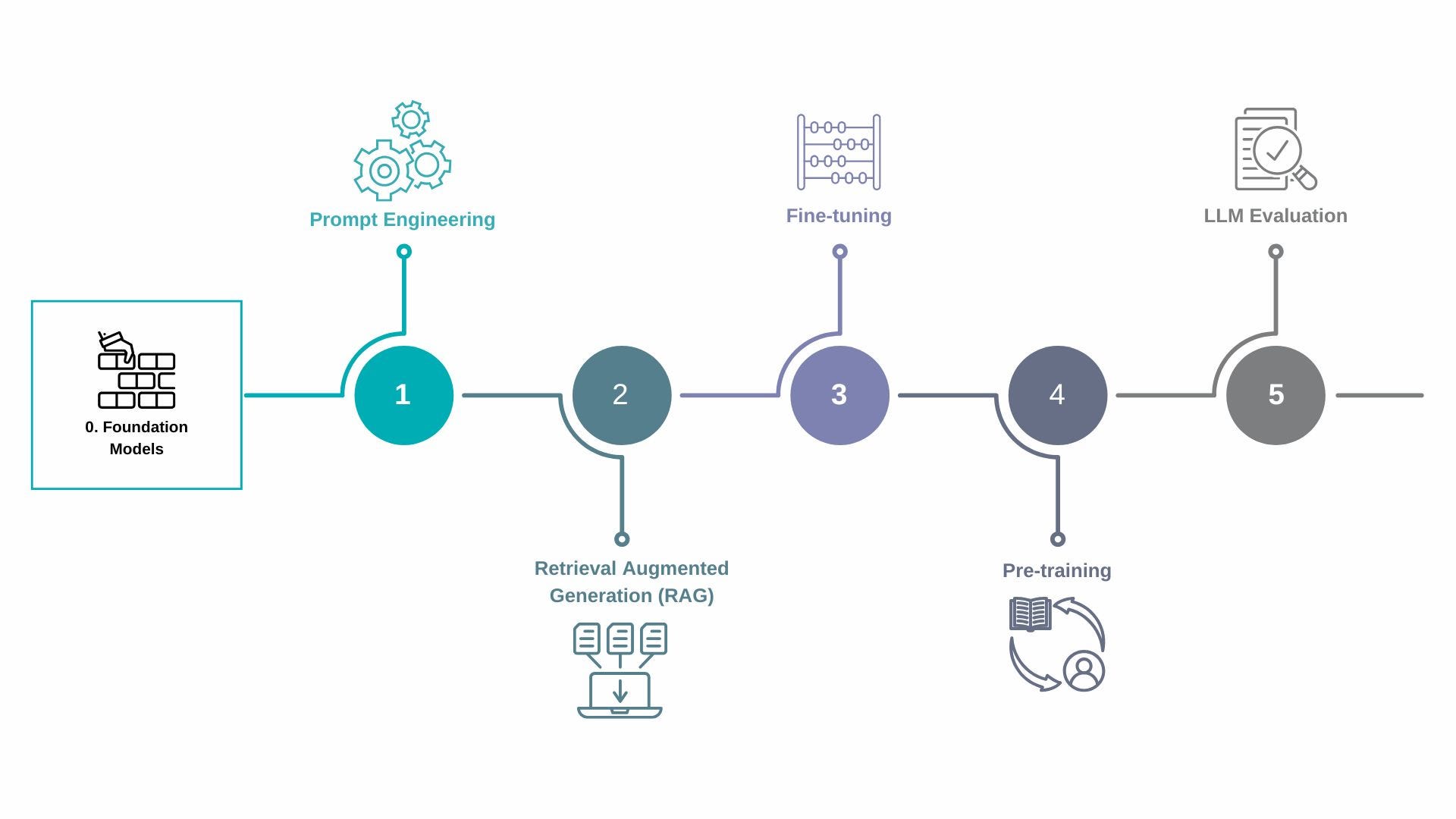
Stage 0: Foundation Models
💡Picture building a house. You need a rock-solid foundation. In AI terms, that’s what foundation models are: large-scale, pre-trained neural networks that can handle tasks like code generation, language translation, and question-answering with ease.
Before setting off to create production-quality GenAI applications, you need to take care of the base language models you’ll use as the foundation for layers of more complex techniques. When you decide to do that, it is important to note that while underlying architectures may differ drastically, foundation models generally fall under two categories: proprietary (such as GPT-3.5 and Gemini) and open source (such as Llama2-70B and DBRX). So yes, Databricks’ very own DBRX is one of these foundational powerhouses and is open-sourced. If it helps, here’s a current list of many open-source GenAI models across different domains that are all free for commercial use.
However, I’m quite curious about DBRX because Databricks describes it in the book to rival proprietary and other open-source models. In fact, when checked, I found that DBRX is already in use by some businesses looking for open-source solutions that give them more control over their data—rather than sending everything off to a third-party service. Businesses like software firms, marketing agencies, and even healthcare organizations are adopting DBRX right now to speed up everything from customer service chatbots to medical research analytics. The mixture-of-experts architecture in DBRX is a standout because it splits tasks among “expert” sub-networks, giving you faster, more accurate responses in areas like code, math, and specialized domain language.
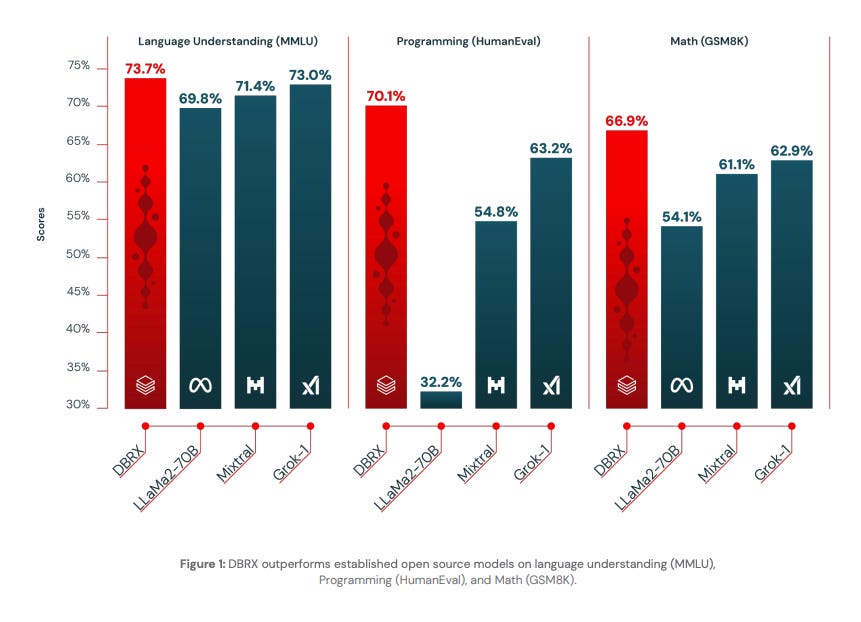
If you are wondering how to get started with DBRX, Databricks makes it pretty straightforward. You can:
- Download the model directly or from open-source repositories (like Hugging Face).
- Use Databricks’s integrated environment, which streamlines deployment.
- Fine-tune DBRX for your specific tasks.
Stage 1: Prompt Engineering
More Than Just Fancy Googling
💡Prompt engineering is essentially the art of asking the right questions to get the best answers.
Have you ever typed a question into Google and ended up sifting through irrelevant stuff? That’s what we’re avoiding here. A well-structured prompt can make or break your AI’s output. For instance, if you run a local bakery, you could ask a generic LLM:
“What do people think about my croissants?”
That might give you a decent answer. But if you prompt it with:
“Summarize the top three compliments and top three complaints about our chocolate croissants from the past two weeks’ online reviews”
You’ll get laser-focused insights. The extra detail in your prompt helps the AI serve up actionable results.
But let’s go further. Databricks has used prompt engineering extensively in their Dolly project (one of their earlier open-source LLMs) to ensure more accurate and context-aware answers for tasks like summarizing technical blog posts or responding to developer FAQs. One publicly discussed example involves using Dolly to summarize a Databricks blog post with a system-level directive, such as “You are a precise technical writer”, followed by the full blog text. This guiding prompt reduced irrelevant details and yielded a concise, high-level summary.
Another experiment focused on responding to frequently asked questions about Databricks runtime and cluster configurations. For instance, you might give Dolly a directive like “You are an expert in Databricks runtime and cluster configurations” and then ask, “Explain how to choose between Standard and High Concurrency clusters for a small data engineering team.” By specifying the role (an expert) and the exact question, Dolly returned more accurate and technically relevant answers with minimal back-and-forth.
The point is essential, whether you’re tinkering with Dolly, DBRX, or any off-the-shelf large language model, remember: a refined prompt can save you hours of back-and-forth and yield much more reliable results. In many ways, it’s the easiest yet most powerful lever you can pull when working with AI.
Stage 2: Retrieval Augmented Generation (RAG)
Bringing Info on Demand
💡RAG stands for Retrieval Augmented Generation (RAG), and the best way I can explain RAG is that it’s the process of optimizing the output of a large language model, so it references an authoritative knowledge base beyond its training data sources.
Think of it like giving your AI model a personal library card. Usually, a language model relies on the information in its training data, which might be out of date or incomplete. But RAG connects your AI to specific, real-time data sources—like your sales database or customer support logs. It lets you bring in supplemental knowledge resources to make an off-the-shelf AI system smarter. RAG won’t change the underlying behavior of the model, but it will improve the quality and accuracy of the responses.
Say you’re running an e-commerce site. A customer asks, “Where’s my recent order?” With RAG, your customer service chatbot can instantly grab details from the shipping database and give the exact status. In contrast, a regular model might just give a generic “We’re working on it” response.
If you are interested in exploring more on RAG, you can checkout frameworks such as LangChain, Haystack, and the Databricks blog (search for “LLM” or “retrieval-augmented” posts) for detailed guides on building retrieval-augmented systems. There’s also a valuable article by Pinecone, which discusses RAG and best practices for scaling.
However, one interesting real-life example I found of RAG in action is Morgan Stanley’s integration of GPT-4 with their proprietary data repositories. This setup allows financial advisors to quickly retrieve and reference up-to-date market research reports, product details, and compliance manuals—all within a single interface. As a result, they can provide more accurate and tailored recommendations to clients without having to navigate multiple documents or systems.
Stage 3: Fine-Tuning Foundation Models
Your Custom AI Tailor
💡Picture you just bought a nice suit or dress off the rack. It’s good but doesn’t fit perfectly. Fine-tuning is like bringing it to a tailor.
Fine-tuning is essentially training a pre-trained model again on new data to focus on a specific domain or skill. It makes the AI more accurate and specialized than a general model. You start with a generic foundation model (like DBRX or GPT-3.5), then train it on your specific data to get a customized solution. For example, you might have thousands of product reviews or industry-specific manuals. By fine-tuning your model on that data, it becomes an “expert” in your domain. Databricks described a real scenario where two engineers built a fine-tuned model in under a month, dedicated to automatically writing database documentation. The results were:
- Faster content generation
- Lower operational costs
- Fewer errors than in a more generic model
A lot of companies use this approach for tasks like:
- Customer service (training AI on internal support knowledge bases)
- Legal contract analysis (feeding the AI past contracts so it understands the language of your industry)
- Financial forecasting (training on proprietary market data for up-to-date predictions)
Stage 4: Pretraining
If Fine-Tuning Is Tailoring, This Is Designing From Scratch
💡Pretraining is the process of training an AI model from scratch on a large, general dataset so it can learn core patterns or language structures. This foundation is later refined for specific tasks or domains in fine-tuning.
Pretraining is the most advanced step. It involves gathering your massive dataset (often terabytes of text or structured data) and building your AI model from the ground up, carefully shaping how it learns patterns, language, or even images. Yes, it’s time-consuming and can be more expensive—but it also gives you complete control over your AI’s capabilities and knowledge.
What does “complete control” mean? First, you’re not relying on someone else’s pre-trained model architecture, domain knowledge, or data. You decide the exact scope of text, images, or other signals your model sees during training. For highly specialized tasks—like drug discovery, advanced medical imaging, or hyper-personalized recommendation systems—this precision can make all the difference.
As an example of how powerful pretraining can be, Databricks made waves by training Stable Diffusion (a model that generates images from text prompts) from scratch for under $50,000—a figure that was once unthinkable. They managed this by carefully curating data, optimizing compute usage, and using the Databricks Lakehouse Platform’s scalable infrastructure.
In practical terms, if you go the pretraining route, you’ll likely need:
- A robust data governance plan, since you’ll pull data from multiple sources
- Access to significant computing resources (think GPU clusters or cloud-based HPC environments)
- Expertise in data processing pipelines so you feed high-quality, well-curated data to your model
Because pretraining is a hefty investment, many businesses consider it only when the payoff is equally big—like unlocking brand-new capabilities or forging ahead in a niche market where no off-the-shelf model exists. But if that kind of game-changing AI is what you’re after, pretraining can be the rocket fuel to get you there.
Stage 5: LLM Evaluation
Check-Ups to Keep You on Track
Finally, we have an evaluation. If you’ve ever had a website that loads super slowly or breaks randomly, you know the importance of regular testing and maintenance. The same goes for LLMs.
💡LLM evaluation is the process of measuring how well a Large Language Model performs across tasks—judging its accuracy, coherence, and usefulness. It helps developers ensure the model meets quality standards and fulfills user needs.
Databricks talks about tools like the “Databricks Gauntlet”—essentially a series of tests to see how well your model performs. Hugging Face’s Leaderboard also ranks AI models based on many tasks, so you can track how your model stacks up. Companies often schedule weekly or monthly “eval runs” to check for:
- Accuracy and helpfulness of responses
- Speed and scalability
- Gaps in knowledge
Because AI models aren’t static—they learn and adapt—this continuous evaluation ensures you’re always putting your best foot forward.
How Do I Get Started?
If you’re new to GenAI (which I guess we all are), here’s a quick-start list:
- Pick a Foundation Model: Check out open-source options like DBRX or go with a popular model from a vendor.
- Practice Prompt Engineering: Tweak your prompts and see how the AI’s output changes.
- Explore RAG: Decide which data sources matter most for your business—maybe it’s your CRM or live inventory data.
- Fine-Tune (If Needed): Start small by fine-tuning on a few thousand data samples. Track improvements.
- Evaluate Often: Benchmark your results, fix what’s not working, and repeat.
In the End, It’s About Creating Value
Remember, GenAI is a tool. It’s not magic, but it can unlock tremendous value—from automating day-to-day tasks to creating new revenue streams—if used wisely. Thought leaders like Andrew Ng often talk about AI’s real power to be in bridging the gap between big ideas and practical solutions.
So, take note of these five stages. Adapt them to your business. Don’t be afraid to experiment—you’ll learn the most by trying different approaches and measuring the outcomes. Before you know it, you’ll have a GenAI system that feels like a natural extension of your team, helping you and your business thrive in an increasingly AI-driven world.
Until next time, thanks for reading! If you enjoyed this, click the button below to subscribe to my Substack for more insights on how data and AI are transforming our world—one innovative step at a time. Let’s keep exploring together!
Notes
- MIT Technology Review via Databricks – Generative AI Report:
- Databricks – Open-Source GenAI Models:
- Databricks DBRX Model (Databricks Marketplace):
- Hugging Face:
- https://huggingface.co/
- Databricks Dolly Project Blog:
- LangChain GitHub Repository:
- Haystack by deepset.ai:
- https://haystack.deepset.ai/
- Databricks Blog (general link):
- Pinecone – Retrieval Augmented Generation:
- OpenAI – Morgan Stanley GPT-4 Integration:
- Databricks Stable Diffusion Blog Post:
- Hugging Face Leaderboard for LLM evaluation:
- Landing AI (Andrew Ng) AI Transformation Playbook: